公司新闻
公司新闻 
-
联系方式
-
邮箱:906460705@qq.com
QQ:906460705
传真:0532-84139338
地址:青岛市黄岛区

类别:公司新闻 来源:米兰平台 发布时间:2025-12-30 10:43:37 浏览:1
NVIDIA宣称Fermi GF100是一个全新架构并非没有道理。不但是通用核算方面,游戏方面它也发生了天翻地覆的改变,简直每一个原有模块都进行了重组:有的砍掉了,有的转移了,有的增强了,还有新增的光栅引擎(Raster Engine)和多形体引擎(PolyMorph Engine)

光栅引擎严格来说光栅引擎并非全新硬件,仅仅此前一切光栅化处理硬件单元的组合,以流水线的方法履行边际/三角形设定(Edge/Triangle Setup)、光栅化(Rasterization)、Z轴紧缩(Z-Culling)等操作,每个时钟循环周期处理8个像素。GF100有四个光栅引擎,每组GPC分配一个,整个中心每周期可处理32个像素。
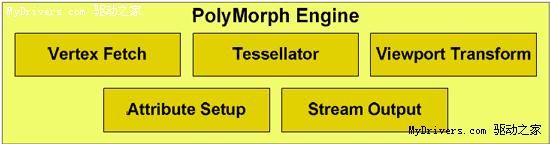
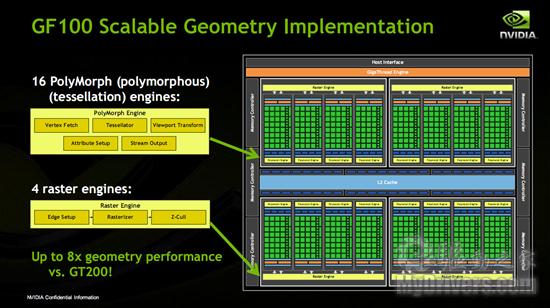
多形体引擎绝非几许单元面目一新、增强15倍罢了,它交融了之前的固定功用硬件单元,使之成为一个有机全体。尽管每一个多形体引擎都是简略的次序规划,但16个作为一体就能像CPU那样进行乱序履行(OoO)了,也便是趋向于并行处理。NVIDIA还特别为这些多形体引擎设置了一个专用通讯通道,让它们在使命处理中保持全体性。
当然,这种改变杂乱得要命,也耗费了NVIDIA工程师许多的精力、资源和时刻。事实上能这么说,多形体引擎正是GF100中心最大的改变地点,也是它无法在上一年及时发布的最大原因。NVIDIA产品营销副总裁Ujesh Desai说过这么一句话:规划这么大的GPU实在是太TMD难了。其实,他指的并不是30亿个晶体管。
这么做也是不得已而为之。考虑到细分曲面单元的几许杂乱性,固定功用流水线现已不适用,整个流水线都要从头平衡。经过多形体引擎的并行规划,几许硬件不再受任何固定单元流水线的限制,可以精确的经过芯片尺寸弹性弹性。和之前的GT200/G92以及AMD比较,GF100走上了另一条路,并且颇有要做CPU的姿势。

在每一组SM阵列里,纹路单元、一二级缓存、ROP单元和各个单元的频率也都彻底不同于以往。每组SM里四个纹路单元,合伙运用12KB一级纹路缓存,并和整个芯片同享768KB二级缓存。每个纹路单元每周期可核算一个纹路寻址、拾取四个纹路采样,并支撑DX11新的紧缩纹路格局。
ROP单元一共48个,分为六组,别离调配一个64-bit显存通道。一切ROP单元和整个芯片同享768KB二级缓存(GT200里是独享)。
除了ROP单元和二级缓存,简直其他一切单元的频率都和Shader频率(NVIDIA暂称之为GPC频率)相关在一起:一级缓存和Sahder单元自身是全速,纹路单元、光栅引擎、多形体引擎则都是一半。关于GF100来说,想超频的话许多当地都要从头来过了。